Hi friends,
In this post, I'm sharing the very important concept of monitoring the performance of microservice using OpenCensus and Zipkin.
Question 1:
How do you monitor the performance of microservice?
Answer:
For monitoring the performance of microservice, I have used OpenCensus and Zipkin tools.
OpenCensus is an open-source project started by google that can emit metrics and traces when it integrates within application code to give us a better understanding of what happens when the application is running.
So, means we have to instrument our application. Instrumentation is how our application produce the events that will help us to have a better understanding of a problem when debugging in production.
For using OpenCensus, we need to integrate it into our code.
Instead of having to manually write code to send traces and metrics on the application while it is running, we just use the OpenCensus libraries.
These libraries exist in several programming languages. By using these libraries as frameworks, we can collect commonly used predefined data.
The data that OpenCensus collects is divided into two groups : metrics and traces.
But how can we see the metrics and traces that OpenCensus collects? By using exporters.
Exporters are the mechanism that we use to send those metrics to other sources (also known as backends) like Prometheus, Zipkin, Stackdriver, Azure Monitor etc.
Metrics: These are the data points that tell us about what is happening in the application e.g. : latency in a service call or user input.
Traces: These are the data that can show how the initial call propagates through the system. Traces help you to find exactly where the application might be having problems.
How does OpenCensus help you?
We can tag every request with an unique ID. Having a unique identifier helps us to correlate all the events involved in each user call, creating a single context.
Once we have the context, OpenCensus helps us expand it by adding traces. Each trace that OpenCensus generates will use the propagated context to help you to visualize request's flow in the system. Having traces allows us to know information like how much time each call took and where exactly the system needs to improve. From all the calls generated, we might identify that the user input has data that we didn't consider and that's what causing a delay in storing data in the cache.
Configure OpenCensus:
Maven Configuration:
<dependency>
<groupId>io.opencensus</groupId>
<artifactId>opencensus-api</artifactId>
<version>${opencensus.version}</version>
</dependency>
<dependency>
<groupId>io.opencensus</groupId>
<artifactId>opencensus-impl</artifactId>
<version>${opencensus.version}</version>
</dependency>
<dependency>
<groupId>io.opencensus</groupId>
<artifactId>opencensus-exporter-trace-zipkin</artifactId>
<version>${opencensus.version}</version>
</dependency>
Inside main() method:
//1. Configure exporter to export traces to Zipkin.
ZipkinTraceExporter.createAndRegister("http://localhost:9411/api/v2/spans", "tracing-to-zipkin-service");
OpenCensus can export traces to different distributed tracing stores (such as Zipkin, Jeager, StackDriver trace). We configure OpenCensus to export to zipkin, which is listening on localhost port 9411 and all of the traces from this program will be associated with a service name tracing-to-zipkin-service.
Configure Sampler:
Configure 100% sample rate, otherwise few traces will be sampled.
TraceConfig traceConfig = racing.getTraceConfig();
TraceParams activeTraceParams = traceConfig.getActiveTraceParams();
traceConfig.updateActiveTraceParams(activeTraceParams.toBuilder().setSampler(Samplers.alwaysSample()).build());
Using the Tracer:
To start a trace, we first need to get a reference to the tracer. It can be retrieved as a global singleton.
Tracer tracer = Tracing.getTracer();
Create a Span:
To create a span in a trace, we used the tracer to start a new span. A span must be closed in order to mark the end of the span. A scoped span implements AutoCloseable, so when used within a try block in java 8, the span will be closed automatically when existing the try block.
try(Scope scope = tracer.spanBuilder("main").startScopedSpan()){
for(int i = 0; i< 10; i++){
doWork(i);
}
}
Using Zipkin:
Zipkin is a java based distributed tracing system to collect and lookup data from distributed systems.
Too many things could happen when a request to an HTTP application is made. A request could include a call to a database engine, to a cache server or any other dependency like another microservice. That's where a service like Zipkin can come in handy.
Zipkin is an open source distributed tracing system based on Dapper's paper from google. Dapper is google's system for its system distributed tracing in production.
Zipkin helps us find out exactly where a request to the application has spent more time.
Whether it is an internal call inside the code or an internal or external API call to another service, we can instrument the system to share a context. Microservices usually share context by correlating requests with a unique ID.
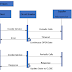
Zipkin Architecture:

Zipkin Components:
- Collector
- Storage
- Search
- Web UI
Using Zipkin:
- Need to add dependency for Zipkin in pom.xml and also add dependency for Zipkin UI.
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.11.7</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.11.7</version>
</dependency>
- Add @EnableZipkinServer annotation on main Springboot application.
Open application.properties in resources and mention following properties:
- spring.application.name = zipkin-server
- server.port = 9411 (default port)
- spring.main.allow-bean-definition-overriding = true (Used when some other bean with same name has already been defined.)
- Management.metrics.web.server.auto-time-requests = false (If prometheus says, there are to meters with same name but different tags names)
That's all for this post.
Thanks for reading!!