Hi Friends,
In this interview post, I'm sharing interview questions-answers on cloud, swagger, database sharding etc.
Question 1:
What is Swagger and what are annotations used by swagger?
Answer:
It is a tool for developing APIs specification with the OpenAPI specification.
Swagger vs OpenAPI:
OpenAPI : Specification
Swagger : Tool for implementing the specification
Annotations used by Swagger:
Question 2:
What are the steps to use Swagger?
Answer:
Steps to use Swagger are defined below:
Question 3:
What is a cloud? What are the benefits of using it?
Answer:
A cloud is actually a collection of web servers [instead of a single server] owned by a 3rd party.
Cloud provides inexpensive ,efficient and flexible alternatives to computers.
Benefits of cloud:
Question 4:
What is sharding ? When we need sharding? How to implement MongoDB sharding?
Answer:
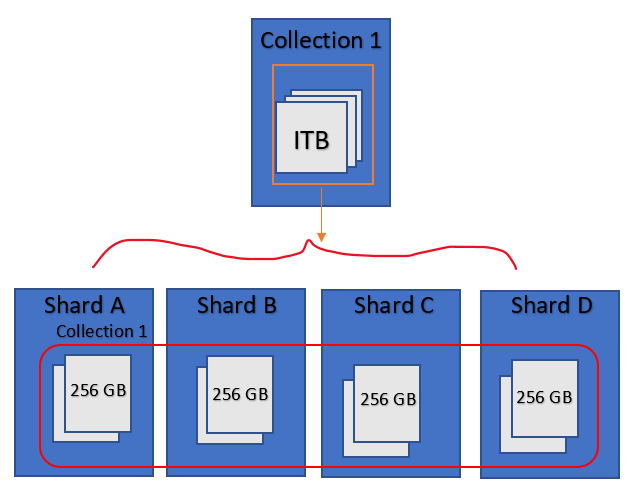
Sharding involves breaking up of one data set into multiple smaller chunks, called logical shards. The logical shards can then be distributed across separate database nodes,referred to as physical shards , which can hold multiple logical shards.
Sharding is a method of splitting and storing a single logical dataset in multiple databases.
Sharding adds more servers to database and automatically balances data and load across various servers. These databases are called shards.
When and why we need sharding?
How to implement MongoDB sharding?
When deploying sharding, we need to choose a key from a collection and split the data using the key's value.
Task that the key performs:

Choosing the correct shard key:
To enhance and optimize the performance , functioning and capability of the DB, we need to choose the correct shard key.
Choosing correct shard key depends upon two factors:
Question 5:
How an application is deployed to Amazon EC2 ?
Answer:
Amazon EC2 offers ability to run applications on cloud.
Steps to deploy application on EC2:
Question 6:
What is serverless Architecture?
Answer:
ServerLess Architecture means: Focus on the application, not the infrastructure.
Serverless is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers.
A serverless application runs in a stateless container that are event-triggered and fully managed by the cloud provider.
Pricing is based on the number of executions rather than pre-purchased compute capacity.
Serverless computing is an execution model where the cloud provider is responsible for executing a piece of code by dynamically allocating the resources.
And only charging for the amount of the resources used to run the code. The code typically runs inside stateless compute containers that can be triggered by a variety of events including HTTP requests, database events, file uploads, scheduled events etc.
The code that is sent to the cloud provider is in the form of a function. Hence serverless is sometimes also referred to as "Functions as a Service".
Following are the FaaS offerings of the major cloud providers:
That's all from this interview.
Hope this post helps everybody in their interviews.
Thanks for reading!!
Question 1:
What is Swagger and what are annotations used by swagger?
Answer:
It is a tool for developing APIs specification with the OpenAPI specification.
Swagger vs OpenAPI:
OpenAPI : Specification
Swagger : Tool for implementing the specification
Annotations used by Swagger:
- @Api
- @ApiModel
- @ApiModelProperty
- @ApiParam
- @ApiResponse
- @ApiResponses
Question 2:
What are the steps to use Swagger?
Answer:
Steps to use Swagger are defined below:
- Put dependencies :
- <dependency>
- <groupId> io.springfox</groupId>
- <artifactId>springfox-swagger2</artifactId>
- </dependency>
- Also add dependency <artifactId>springfox-swagger-ui</artifactId>
- Create a swagger config file [.java file] annotated with @EnableSwagger2 and should have accompanying @Configuration annotation. In this class, create a Docket bean by calling api() method.
- Use @Api on controller class.
- Use @ApiOperation and @ApiResponses on methods.
- Use @ApiModel on entity class.
Question 3:
What is a cloud? What are the benefits of using it?
Answer:
A cloud is actually a collection of web servers [instead of a single server] owned by a 3rd party.
Cloud provides inexpensive ,efficient and flexible alternatives to computers.
Benefits of cloud:
- No need of extra space required to keep all the hardware [Servers, digital storage]
- Companies don't need to buy software or software license for all it's employees. They just pay a small fees to the cloud computing company to let their employees access a suite of software online.
- It also reduces IT problems and costs.
Question 4:
What is sharding ? When we need sharding? How to implement MongoDB sharding?
Answer:
Sharding involves breaking up of one data set into multiple smaller chunks, called logical shards. The logical shards can then be distributed across separate database nodes,referred to as physical shards , which can hold multiple logical shards.
Sharding is a method of splitting and storing a single logical dataset in multiple databases.
Sharding adds more servers to database and automatically balances data and load across various servers. These databases are called shards.
When and why we need sharding?
- When the dataset outgrows the storage capacity of a single database instance.
- When a single instance of DB is unable to manage write operations.
How to implement MongoDB sharding?
When deploying sharding, we need to choose a key from a collection and split the data using the key's value.
Task that the key performs:
- Determines document distribution among the different shards in a cluster.

Choosing the correct shard key:
To enhance and optimize the performance , functioning and capability of the DB, we need to choose the correct shard key.
Choosing correct shard key depends upon two factors:
- The schema of the data.
- The way database applications query and perform write operations.
Question 5:
How an application is deployed to Amazon EC2 ?
Answer:
Amazon EC2 offers ability to run applications on cloud.
Steps to deploy application on EC2:
- Launch an EC2 instance and SSH into it. This instance needs to be created first on AWS Console [console.aws.amazon.com]. And we should have certificate to connect to EC2 instance.
- Install Node on EC2, if our app is in angular.
- Copy paste code on EC2 and install dependencies.
- Start server to run.
Another way:
Suppose we have Spring Boot application.
- Build out Spring Boot app in our local computer. Make .jar file.
- Upload this .jar file on S3.
- Create EC2 instance.
- SSH into EC2 from our local computer.
- Now, we are in EC2 instance.
- Now install JDK.
- And using java - .jar file path, we can run our application.
Question 6:
What is serverless Architecture?
Answer:
ServerLess Architecture means: Focus on the application, not the infrastructure.
Serverless is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers.
A serverless application runs in a stateless container that are event-triggered and fully managed by the cloud provider.
Pricing is based on the number of executions rather than pre-purchased compute capacity.
Serverless computing is an execution model where the cloud provider is responsible for executing a piece of code by dynamically allocating the resources.
And only charging for the amount of the resources used to run the code. The code typically runs inside stateless compute containers that can be triggered by a variety of events including HTTP requests, database events, file uploads, scheduled events etc.
The code that is sent to the cloud provider is in the form of a function. Hence serverless is sometimes also referred to as "Functions as a Service".
Following are the FaaS offerings of the major cloud providers:
- AWS Lambdas
- Microsoft Azure : Azure Functions
- Google Cloud : Cloud Functions
- IBM Openwhishk
- Auth0 Webtask
That's all from this interview.
Hope this post helps everybody in their interviews.
Thanks for reading!!